














Впервые мысль использовать электронно-вычислительные машины для перевода текстов была высказана в 1947 году в США, сразу после появления первых ЭВМ. Первая публичная демонстрация машинного перевода состоялась в 1954 году. Та система была очень примитивной: она имела словарь всего из 250 слов, 6 грамматических правил и могла перевести лишь несколько простых фраз. Но эксперимент получил широкий резонанс: начались исследования в странах по всему миру и в том числе в СССР. Как же работает современная система машинного перевода — об этом в сегодняшнем выпуске!
В основе современных систем лежит алгоритм перевода, использующий формальную грамматику языков и статистические данные. Чтобы выучить язык, система сравнивает тысячи параллельных текстов — содержащих одну и ту же информацию, но на разных языках. Для каждого изученного текста система строит список уникальных признаков. Например, редко используемые слова и специальные знаки, которые встречаются в тексте с определенной частотой.

В системах машинного перевода, как правило, три основные части: модель перевода, модель языка и декодер. Модель перевода — это таблица, в которой для всех слов и фраз на одном языке перечислены возможные переводы на другой язык с указанием вероятности этих переводов. Система сравнивает не только отдельные слова, но и словосочетания из нескольких слов, идущих подряд. Модели перевода для каждой пары языков содержат миллионы пар слов и словосочетаний. Что касается модели языка, то она создается системой на этапе изучения текстов.
Переводом занимается декодер. Он проводит морфологический и синтаксический анализ текста и для каждого предложения подбирает все варианты перевода с сортировкой по убыванию вероятности. Затем все полученные варианты декодер оценивает с помощью модели языка на частоту употребления и выбирает предложение с наилучшим сочетанием вероятности и частоты.
![]()
Системы машинного перевода можно использовать не только для работы с текстами, но и для перевода отдельных слов. Они содержат полноценные словари с подробными карточками слов и устойчивых выражений. Эти карточки система составляет на основе статистических данных, опираясь на правила языка. Для машинного словаря она отбирает только словарные формы слов и устойчивые выражения. Система проводит морфологический и синтаксический анализ, определяет часть речи, словарную форму слова и устанавливает границы словосочетаний. Эта информация помогает отсеивать неполные словосочетания. Чтобы избежать ошибок и опечаток, алгоритм, основанный на технологии машинного обучения, проверяет все потенциальные пары переводов и отсеивает ненадёжные.
Близкие по значению переводы группируются системой с помощью словарей синонимов. В них попадают слова, которые часто переводятся на другой язык одинаково или образуют словосочетания с одинаковыми словами. В результате машинный словарь получает всё, что ему необходимо знать о каждом слове и выражении: его словарную форму, часть речи, значения и синонимы. Некоторые системы для наглядности добавляют к переводам примеры, которые берут из параллельных текстов.
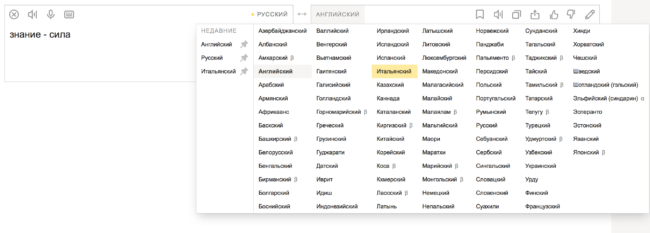
Использование статистических данных позволяет системам машинного перевода меняться вместе с языком. Если люди начинают писать какое-то слово по-другому, система видит это, как только к ней попадают новые тексты. Чтобы улучшать качество перевода, систему регулярно обновляют и проводят проверки. Впрочем, высококачественный машинный перевод текстов по-прежнему недостижим. Однако он значительно облегчает и ускоряет работу переводчикам.
https://hi-news.ru/eto-interesno/kak-eto-rabotaet-mashinnyj-perevod.html