














Как самостоятельная дисциплина компьютерное зрение зародилось в начале 50-х годов прошлого века. В 1951 году Джон фон Нейман предложил анализировать микроснимки при помощи компьютеров путём сравнения яркости соседних частей изображения. В 60-е годы начались исследования в области распознавания машинного и рукописного текста. Тогда же были сделаны первые попытки моделирования нейронной сети. Первым устройством, способным распознавать буквы, стала разработка Фрэнка Розенблатта — персептроном. А в 70-х годах ученые стали изучать зрительную систему человека с целью её формализации и реализации в виде алгоритмов. Такой подход был призван позволить распознавать объекты на изображениях. Как же работает современное компьютерное зрение – об этом в сегодняшнем выпуске.
Итак, компьютерное зрение — это набор методов, позволяющих обучить машину извлекать информацию из изображения или видео. Чтобы компьютер находил на изображениях определенные объекты, его необходимо научить. Для этого составляется огромная обучающая выборка, например, из фотографий, часть из которых содержат искомый объект, а другая часть — напротив, не содержит. Далее в дело вступает машинное обучение. Компьютер анализирует изображения из выборки, определяет, какие признаки и их комбинации указывают на наличие искомых объектов, и просчитывает их значимость.

После завершения обучения компьютерное зрение можно применять в деле. Для компьютера изображение — это набор пикселей, у каждого из которых есть своё значение яркости или цвета. Чтобы машина смогла получить представление о содержимом картинки, ее обрабатывают с помощью специальных алгоритмов. Сначала выявляют потенциально значимые места. Это можно делать несколькими способами. Например, исходное изображение несколько раз подвергают размытию по Гауссу, используя разный радиус размытия. Затем результаты сравнивают друг с другом. Это позволяет выявить наиболее контрастные фрагменты — яркие пятна и изломы линий.

После того как значимые места найдены, компьютер описывает их в числах. Запись фрагмента картинки в числовом виде называется дескриптором. С помощью дескрипторов можно достаточно точно сравнивать фрагменты изображения без использования самих фрагментов. Чтобы ускорить вычисления, компьютер проводит кластеризацию или распределение дескрипторов по группам. В один и тот же кластер попадают похожие дескрипторы с разных изображений. После кластеризации важным становится лишь номер кластера с дескрипторами, наиболее похожими на данный. Переход от дескриптора к номеру кластера называется квантованием, а сам номер кластера — квантованным дескриптором. Квантование существенно сокращает объём данных, которые необходимо обработать компьютеру.
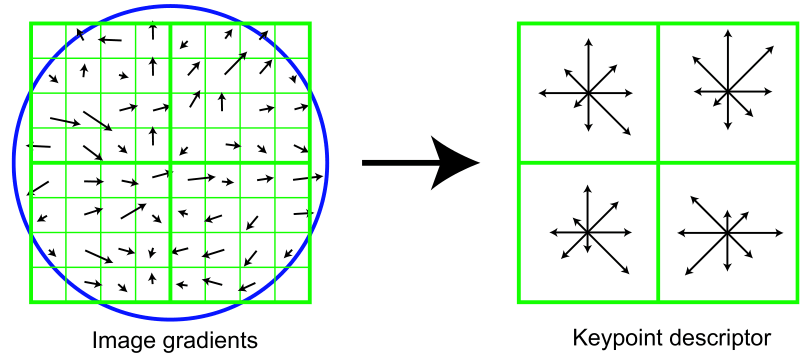
Опираясь на квантованные дескрипторы, компьютер может сравнивать изображения и распознавать на них объекты. Он сопоставляет наборы квантованных дескрипторов с разных изображений и делает вывод о том, насколько они или их отдельные фрагменты похожи. Такое сравнение в том числе используется поисковыми системами для поиска по загруженной картинке.